

This article is going to be very useful for candidates appearing for SQL Interview.
SQL (Structured Query Language) is a specialized language used for managing and manipulating relational databases. It allows users to create, read, update, and delete database records through simple, declarative commands. SQL is crucial for interacting with database management systems (DBMS) such as MySQL, PostgreSQL, Oracle, and SQL Server.
SQL interviews often focus on assessing a candidate’s ability to write efficient and correct SQL queries, understand database design and normalization principles, and optimize query performance. Common topics include SELECT statements, JOIN operations, indexing, stored procedures, transactions, and error handling. Interviewers may also test problem-solving skills with real-world scenarios, requiring a deep understanding of how to retrieve, manipulate, and maintain data integrity within relational databases.
Common SQL Interview Questions with Answers
1. How do you retrieve all data from a specific table ?
SELECT * FROM table_name;
2. How can you filter records in SQL based on a condition ?
SELECT column1, column2 FROM table_name WHERE condition;
3. How do you combine data from multiple tables? Describe different JOIN types.
Inner Join : Returns records that have matching values in both tables.
SELECT columns FROM table1 INNER JOIN table2 ON table1.common_field = table2.common_field;
Left Join : Returns all records from the left table, and the matched records from the right table. The result is NULL from the right side if there is no match.
SELECT columns FROM table1 LEFT JOIN table2 ON table1.common_field = table2.common_field;
Right Join : Returns all records from the right table, and the matched records from the left table. The result is NULL from the left side when there is no match.
SELECT columns FROM table1 RIGHT JOIN table2 ON table1.common_field = table2.common_field;
Full Join : Returns all records when there is a match in either left or right table.
SELECT columns FROM table1 FULL JOIN table2 ON table1.common_field = table2.common_field;
Cross Join : Returns the Cartesian product of both tables.
SELECT columns FROM table1 CROSS JOIN table2;
4. What is the difference between WHERE and HAVING clauses in SQL?
WHERE: Used to filter records before any groupings are made.
SELECT column1, column2 FROM table_name WHERE condition;
HAVING: Used to filter records after a GROUP BY has been applied.
SELECT column1, SUM(column2) FROM table_name GROUP BY column1 HAVING condition;
5. How do you count the number of rows in a table ?
SELECT COUNT(*) FROM table_name;
6. How can you calculate aggregate values like SUM, AVG, MIN, and MAX in SQL ?
SELECT SUM(column_name) AS total,
AVG(column_name) AS average,
MIN(column_name) AS minimum,
MAX(column_name) AS maximum
FROM table_name;
7. What is a subquery, and where can it be used in SQL?
A subquery is a query nested inside another query. It can be used in SELECT, INSERT, UPDATE, and DELETE statements as well as in clauses like WHERE, FROM, and HAVING.
SELECT column_name FROM table_name WHERE column_name = (SELECT column_name FROM table_name WHERE condition);
8. Differentiate between correlated and non-correlated subqueries with examples.
Non-correlated subquery: Independent query which can be executed on its own.
SELECT column_name FROM table_name WHERE column_name = (SELECT MAX(column_name) FROM table_name2);
Correlated subquery: Depends on the outer query for its value.
SELECT column_name
FROM table_name t1
WHERE column_name = (SELECT MAX(column_name)
FROM table_name2 t2
WHERE t1.common_field = t2.common_field);
9. How do you optimize a slow-running SQL query ?
- Indexes: Create indexes on columns used in WHERE, JOIN, ORDER BY, and GROUP BY clauses.
- Avoid SELECT *: Select only necessary columns.
- Query refactoring: Simplify complex queries.
- Use JOINs instead of subqueries when possible.
- Analyze and optimize database schema.
- Use proper indexing strategies and database statistics.
- Use database-specific optimization tools.
10. What are indexes, and how do they improve query performance ?
Indexes are database objects that improve the speed of data retrieval operations on a table by providing quick access to rows.
11. How do you perform insert, update, and delete operations in SQL?
INSERT INTO table_name (column1, column2) VALUES (value1, value2); UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition; DELETE FROM table_name WHERE condition;
12. Explain the difference between the TRUNCATE and DELETE commands.
DELETE: Removes rows from a table based on a condition. Can be rolled back.
TRUNCATE: Removes all rows from a table, resets identity columns, and cannot be rolled back.
DELETE FROM table_name WHERE condition; TRUNCATE TABLE table_name;
13. How do you create, modify, and drop tables in SQL ?
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
);
ALTER TABLE table_name
ADD column_name datatype;
ALTER TABLE table_name
MODIFY column_name new_datatype;
ALTER TABLE table_name
DROP COLUMN column_name;
DROP TABLE table_name;
14. What are constraints in SQL, and how do you enforce them ?
Constraints are rules enforced on data columns to ensure data integrity and consistency.
CREATE TABLE table_name (
column_name datatype NOT NULL
);
CREATE TABLE table_name (
column_name datatype UNIQUE
);
CREATE TABLE table_name (
column_name datatype PRIMARY KEY
);
CREATE TABLE table_name (
column_name datatype,
CONSTRAINT fk_name FOREIGN KEY (column_name) REFERENCES other_table (other_column)
);
CREATE TABLE table_name (
column_name datatype,
CONSTRAINT check_name CHECK (condition)
);
15. What is a transaction in SQL, and why is it important ?
A transaction is a sequence of one or more SQL operations treated as a single unit of work. It is important for ensuring data integrity and consistency, allowing for commit or rollback actions.
16. Describe the use of COMMIT, ROLLBACK, and SAVEPOINT in SQL transactions.
COMMIT: Saves all changes made in the transaction.
ROLLBACK: Undoes all changes made in the transaction.
SAVEPOINT: Sets a savepoint within a transaction to which you can later roll back.
COMMIT; ROLLBACK; SAVEPOINT savepoint_name;
17. What is database normalization, and why is it necessary ?
Database normalization is the process of structuring a relational database to minimize redundancy and dependency. It is necessary to ensure data integrity, reduce data redundancy, and improve query performance.
18. Explain the different normal forms (1NF, 2NF, 3NF, BCNF) with examples.
1NF (First Normal Form): Ensures each column contains atomic, indivisible values, and each record is unique.
2NF (Second Normal Form): Meets 1NF requirements and has no partial dependency (no non-prime attribute is dependent on any proper subset of any candidate key).
3NF (Third Normal Form): Meets 2NF requirements and has no transitive dependency (non-prime attributes are not dependent on other non-prime attributes).
BCNF (Boyce-Codd Normal Form): Meets 3NF requirements, and for every functional dependency X -> Y, X should be a super key.

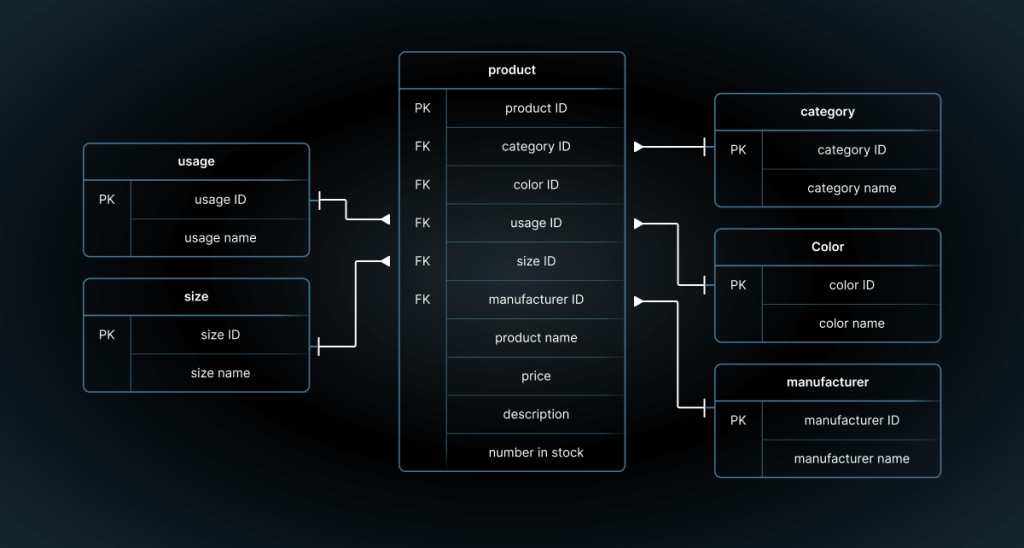
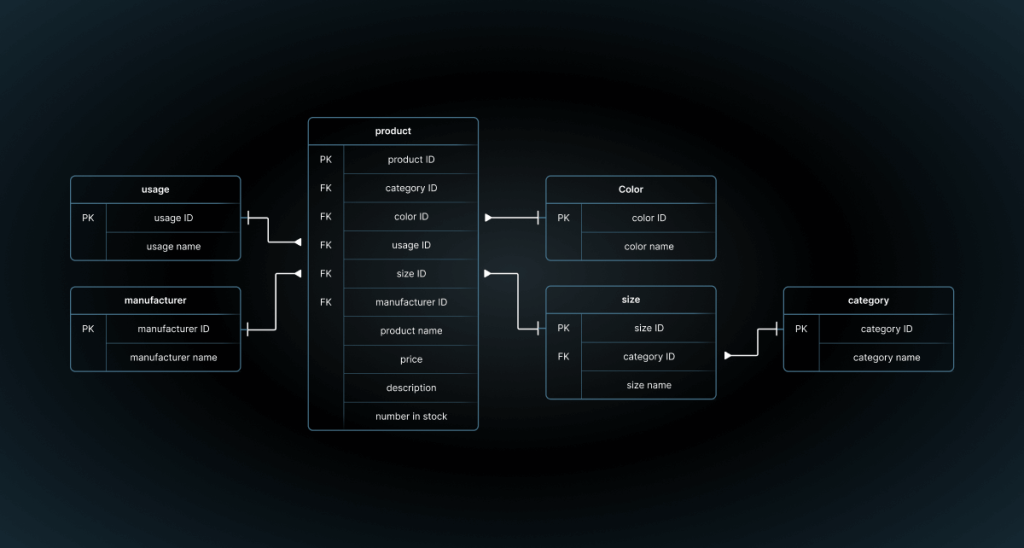
19. What are window functions in SQL, and how are they used ?
Window functions perform calculations across a set of table rows that are somehow related to the current row. Unlike aggregate functions, window functions do not cause rows to become grouped into a single output row.
SELECT employee_id,
salary,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
FROM employees;
20. Explain ROW_NUMBER(), RANK(), and DENSE_RANK() in SQL.
ROW_NUMBER(): Assigns a unique sequential integer to rows within a partition of a result set.
RANK(): Assigns a rank to each row within a partition of a result set, with gaps in ranking for ties.
DENSE_RANK(): Similar to RANK(), but assigns consecutive ranks without gaps for ties.
SELECT employee_id,
ROW_NUMBER() OVER (ORDER BY salary) AS row_num
FROM employees;
SELECT employee_id,
RANK() OVER (ORDER BY salary) AS rank
FROM employees;
SELECT employee_id,
DENSE_RANK() OVER (ORDER BY salary) AS dense_rank
FROM employees;

